

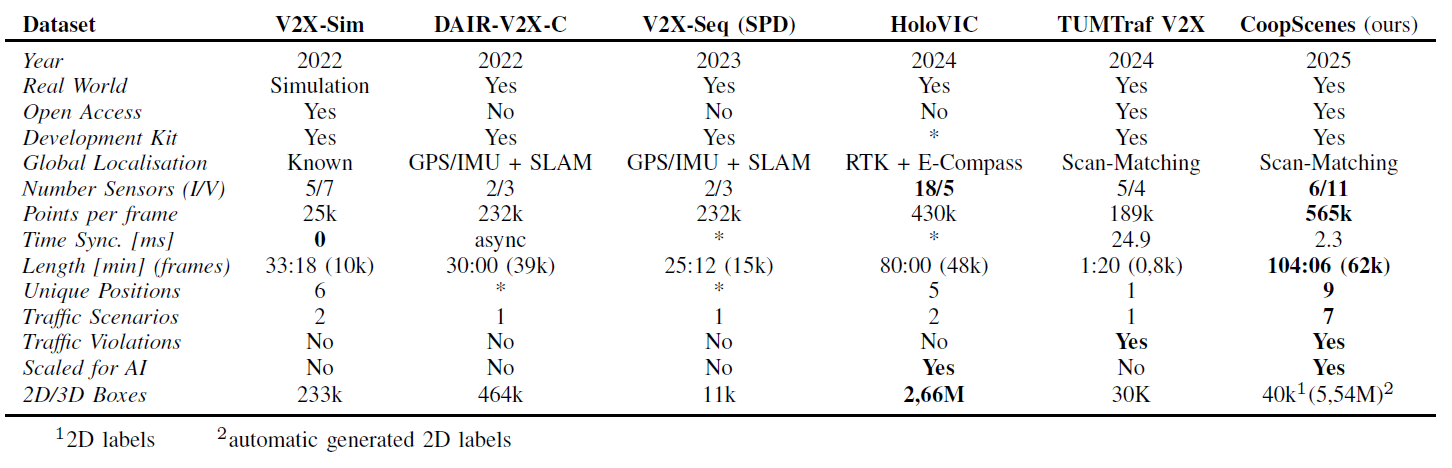
Setup







The increasing complexity of urban environments has underscored the potential of effective collective perception systems. To address these challenges, we present the CoopScenes dataset, a large-scale, multi-scene dataset that provides synchronized sensor data from both the ego-vehicle and the supporting infrastructure. The dataset provides 104 minutes of spatially and temporally synchronized data at 10 Hz, resulting in 62,000 frames. It achieves competitive synchronization with a mean deviation of only 2.3 ms. It includes a novel procedure for precise registration of point cloud data from the ego-vehicle and infrastructure sensors, automated annotation pipelines, and an open-source anonymization pipeline for faces and license plates. Covering 9 diverse scenes with 100 maneuvers, the dataset features scenarios such as public transport hubs, city construction sites, and high-speed rural roads across three cities in the Stuttgart region, Germany. The full dataset amounts to 527 GB of data and is provided in the .4mse format and is easily accessible through our comprehensive development kit. By providing precise, large-scale data, CoopScenes facilitates research in collective perception, real-time sensor registration, and cooperative intelligent systems for urban mobility, including machine learning-based approaches.
Our vehicle agent is a modified Mercedes Sprinter, designed with spacious, bus-like seating and an elevated roof for easy entry and comfortable standing room inside the cabin. Equipped with a complete AD perception sensor suite, it features six cameras arranged for 360° coverage, including a secondary front-facing camera optimized for stereo applications (note: there is no dedicated rear camera). The vehicle is also outfitted with three LiDAR sensors to capture mid- and near-range perspectives and a high-precision INS system (integrating GNSS and IMU with correction data) to ensure accurate localization and navigation data.
Our sensor tower shares the same advanced specification as the vehicle agent, serving as a highly adaptable observation unit. It features two movable arms, each mounted with a camera and a solid-state LiDAR unit, alongside a 360° Ouster OS LiDAR (128 rays) positioned at the top for comprehensive coverage. The tower is equipped with a GNSS system and achieves nanosecond-level synchronization with the vehicle’s data stream via PTP, using GNSS-triggered timing. This setup ensures precise alignment of all data within a few milliseconds. Operating independently, the tower relies on a 5G mobile connection, dual 100 Ah (24V) batteries, and a solar panel, making it fully self-sufficient in the field.
For our initial publication we've gathered data from 9 different locations across Stuttgart, Esslingen, and Waiblingen in Baden-Württemberg, Germany. Each location is precisely mapped in a Google Earth project, making it easy to revisit and verify positioning.
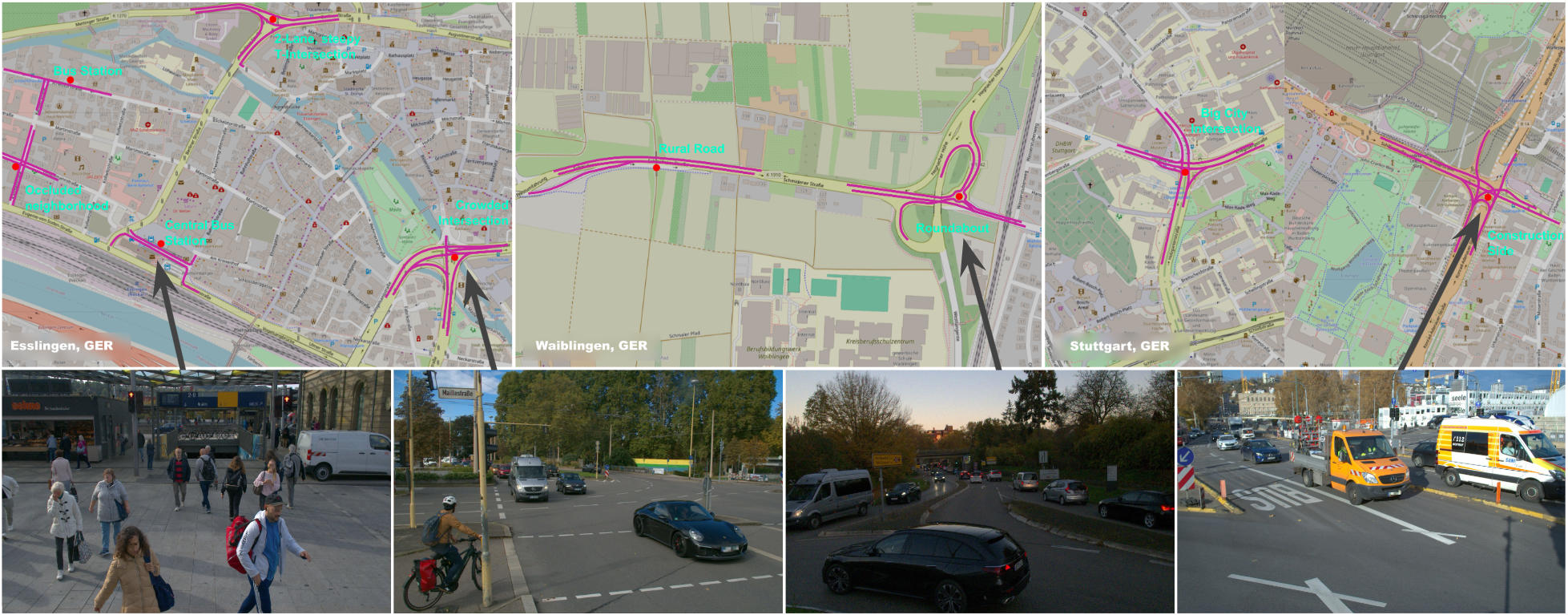
Given the varying camera placements and angles on our infrastructure towers, each site requires tailored calibration. At each location, a series of defined maneuvers was driven multiple times to ensure consistency. In total, we offer around 104 minutes of fully synchronized and anonymized data, with our anonymization process and a comprehensive development report to be made publicly available.







Since we are a small lab with limited resources and labeling is cost-intensive, we explored scalable alternatives through automated annotation and anonymization pipelines. Rather than focusing on traditional detection benchmarks, CoopScenes emphasizes infrastructure-vehicle interoperability. Using mighty offline Transformer models like Co-DETR, we generated high-quality 2D instance labels, achieving an F1-score of 89.4% (try to beat that ;D) for vehicles (Note: The test set is meticulously hand-labeled and may not align perfectly with the model’s output format). The dataset includes over 5.5 million detected instances and will be extended with 3D labels and hand-annotated subsets to support benchmarking and further model development.

To enable sensor interoperation, all sensors are extrinsically calibrated relative to a designated agent origin—either the vehicle's top sensor or the tower—reducing the problem to a single inter-agent transformation. Using the tower as the global origin, we estimate the inter-agent transformation via LiDAR-based KISS-ICP, supported by Fast Point Feature Histograms (FPFH). Initial alignment is selected from GNSS-proximal frames using RANSAC and refined with ICP, then clustered with DBSCAN. Transformations are propagated, enabling estimates even without direct sensor overlap. Reliable transformations are refined per frame; others are interpolated from odometry, assuming a static tower.

Quantitative evaluation of cross-agent point cloud projections onto images is challenging; therefore, we focus on qualitative assessments. As shown, even under challenging conditions—such as high speeds and distant objects—the projections exhibit competitive alignment quality.
We are pleased to present our dataset, with a strong emphasis on anonymization to ensure privacy protection. Recent research has questioned whether object detectors trained on anonymized data perform comparably to those trained on unaltered data. To address this concern, we developed BlurScene, a face and license plate detector based on Faster R-CNN, available at github. Trained on publicly available datasets and evaluated on our labeled CoopScenes test set, we distinguished between identifiable and non-identifiable instances to optimize the balance between privacy and utility. Although the model prioritizes high recall, we selected an operating point optimized for precision to minimize unnecessary blur.
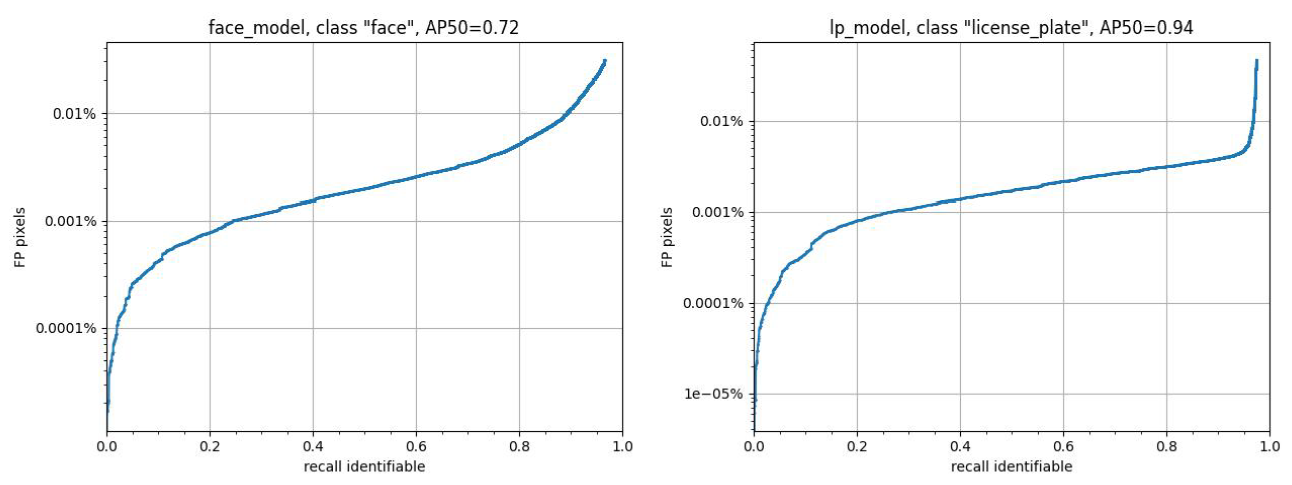
Currently, anonymization is applied using an adaptive mosaic filter for a more natural appearance. We are actively exploring advanced anonymization through style transfer techniques such as StyleCLIP, CycleGAN, and DeepPrivacy2. Until then, all code, data, and development strategies are open source—and we welcome contributions from the community.
We offer 3D RGB point clouds generated by integrating data from LiDAR and cameras, providing detailed spatial and color information for enhanced scene understanding.


A key component of the dataset is the viewpoint from the observing infrastructure, providing a comprehensive perspective from the environment. Every color indicates another sensor.

We provide a high-quality stereo camera system designed for precise depth perception and 3D imaging (front-facing camera only), all accessible through our research and development kit.

@INPROCEEDINGS{11097591,
author = {Vosshans, Marcel and Baumann, Alexander and Drueppel, Matthias and Ait-Aider, Omar and Mezouar, Youcef and Dang, Thao and Enzweiler, Markus},
booktitle = {2025 IEEE Intelligent Vehicles Symposium (IV)},
title = {CoopScenes: Multi-Scene Infrastructure and Vehicle Data for Advancing Collective Perception in Autonomous Driving},
year = {2025},
pages = {1040-1047},
keywords = {Point cloud compression;Roads;Urban areas;Pipelines;Real-time systems;Information filtering;Synchronization;Intelligent systems;License plate recognition;Information integrity},
doi = {10.1109/IV64158.2025.11097591}}